Introduction to OpenAI.Stream
The demand for real-time AI responses is growing rapidly. From chatbots to dynamic content generation, developers want instant feedback from AI models without waiting for the entire response to be generated. This is where openai.stream comes into play. OpenAI.Stream enables live, token-by-token responses from OpenAI models, bringing applications closer to real-time AI interactions. By leveraging streaming support in the OpenAI API, developers can deliver faster, more engaging, and interactive user experiences. In this guide, we’ll explore what OpenAI.Stream is, how it works, and how you can integrate it into your projects for seamless real-time AI.
What is OpenAI.Stream?
OpenAI.Stream is a feature of the OpenAI API that allows developers to receive generated responses incrementally, as they are created. Instead of waiting for the AI to finish generating a complete response, streaming enables you to process and display output as soon as new tokens are available. This lowers perceived latency and improves user experience—especially in conversational interfaces and content editing tools.
Primary Use Cases:
- Real-time chatbots and virtual assistants
- Interactive content creation tools
- Live content moderation
- Streaming generative outputs (e.g., stories, code)
Key Benefits:
- Low Latency: Immediate access to the first tokens generated, reducing wait times.
- Real-Time Feedback: Users see results as they happen, boosting interactivity.
- Scalability: Efficient for high-frequency messaging or multi-user applications.
OpenAI.Stream is at the core of the OpenAI streaming API, powering real-time AI responses across a variety of modern applications.
How OpenAI Streaming Works
At a high level, OpenAI.Stream establishes a persistent HTTP connection between your application and the OpenAI API. When you make a streaming request, the model starts sending tokens (words or subwords) as soon as they are generated, rather than waiting for the entire output to complete.
Request-Response Flow
Here’s a simplified flow of how streaming works:
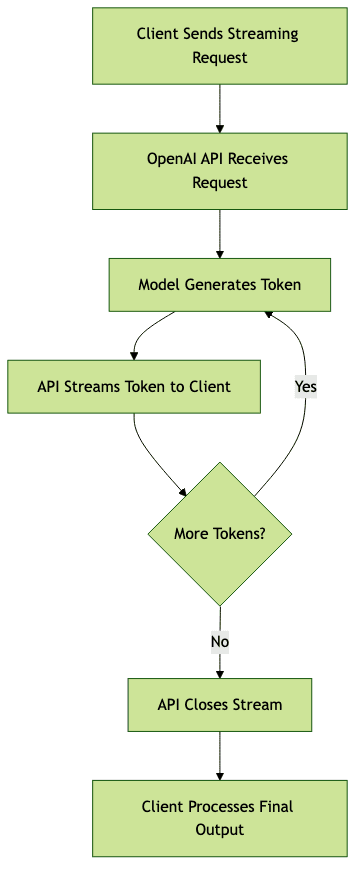
Standard vs. Streaming Completions
- Standard Completion: Waits for the full response before returning data. Suitable for short, simple requests.
- Streaming Completion: Returns tokens as soon as they’re generated. Ideal for conversational AI, long-form content, and interactive applications.
Real-World Streaming Scenarios
- Chatbots: Users see AI typing responses in real time.
- Coding assistants: Code is suggested line by line.
- Content moderation: Potentially harmful content is flagged as soon as detected, instead of after the full response.
OpenAI streaming implementation is transforming how developers build responsive, real-time AI applications.
Implementing OpenAI.Stream in Your Projects
Ready to integrate openai.stream? Here’s a step-by-step guide to get you started.
Setting Up Your API Keys
First, sign up for an OpenAI account and generate your API key from the
OpenAI API dashboard
.1import os
2import openai
3
4# Set up your OpenAI API key
5openai.api_key = os.getenv(\"OPENAI_API_KEY\")
6Making Your First Streaming Request
To initiate a streaming chat completion, set
stream=True in your API call. Here’s a Python example using the official OpenAI library:1response = openai.ChatCompletion.create(
2 model=\"gpt-3.5-turbo\",
3 messages=[{"role": "user", "content": "Tell me a story about AI in space."}],
4 stream=True # Enable streaming
5)
6Handling Streamed Responses
Streamed responses are returned as a generator. You can process each chunk (token or message part) as it arrives:
1for chunk in response:
2 if 'choices' in chunk:
3 delta = chunk['choices'][0]['delta']
4 if 'content' in delta:
5 print(delta['content'], end='', flush=True)
6This approach enables live updates in your UI or CLI application. The same pattern applies for streaming chat completions and other OpenAI API examples.
Tip: For JavaScript/Node.js developers, use theopenai
npm package and handle the stream withReadableStreamor event listeners.
Best Practices for OpenAI.Stream
To get the most out of OpenAI stream, follow these streaming best practices:
Latency Optimization
- Minimize prompt complexity: Shorter, more focused prompts generate faster responses.
- Efficient connection handling: Keep connections alive and avoid unnecessary reconnections.
- Network optimization: Use reliable, low-latency servers near OpenAI endpoints.
Content Moderation Challenges
- Streamed content may need to be moderated in real-time. Implement token-level content checks or use OpenAI’s content moderation tools alongside your stream.
Error Handling
- Monitor for network interruptions and API errors.
- Implement retries with exponential backoff for transient failures.
- Detect and handle partial/incomplete results gracefully to maintain a seamless user experience.
Adhering to these OpenAI stream best practices ensures robust, responsive, and safe AI-powered products.
Tools & Libraries to Enhance Streaming
Enhance your streaming implementation with these helpful tools:
- OpenAI Stream Parser: Parses OpenAI streaming API responses efficiently in JavaScript/TypeScript projects.
- OpenAI Python SDK: Native support for streaming completions.
- LangChain: Abstraction for chaining streamed outputs from OpenAI and other providers.
- SSE (Server-Sent Events) Libraries: For custom handling of HTTP streaming in web frameworks.
- Third-party wrappers: Community-driven libraries for specific frameworks (e.g., openai-edge, openai-streams for Node.js).
These tools accelerate OpenAI streaming implementation and help you build production-ready, scalable applications.
Common Challenges and How to Overcome Them
Rate Limits
OpenAI API enforces rate limits per account and per model. Use exponential backoff and queue requests to avoid hitting these limits. Monitor API headers for your quota status.
Handling Partial Results
Streaming means responses may be interrupted. Design your UI/UX to indicate when streaming is incomplete, and allow users to retry or resume from the last token.
Debugging Stream Issues
- Log all received chunks for post-mortem analysis.
- Use request IDs to track problematic sessions.
- Test with mock streams to simulate various network and server scenarios.
By proactively addressing these common OpenAI stream issues, you ensure a smoother developer and user experience.
Conclusion
OpenAI.Stream unlocks the power of real-time AI responses, enabling developers to build applications that are interactive, responsive, and engaging. By following best practices, leveraging the right tools, and understanding the streaming process, you can harness the full potential of the OpenAI streaming API. Start building with openai.stream today and deliver next-level AI experiences.
Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ