Implementing Real-Time Transcription: A Guide to Live Audio Transcription and Realtime Speech to Text
Learn how to implement real-time transcription in your applications with this comprehensive guide. Discover the technologies behind live audio transcription, step-by-step implementation using VideoSDK, and best practices for optimizing transcription accuracy and performance.
We've all been there – trying to collect notes during an important video call while simultaneously staying engaged in the conversation. Despite our best efforts, crucial details slip through the cracks. Later, we find ourselves scrolling through lengthy recordings, desperately searching for that specific feature discussion or client requirement mentioned somewhere in the hour-long meeting.
Understanding Real-Time Transcription and Its Applications
What is Real-Time Transcription?
Real-time transcription (also known as live audio transcription and realtime speech to text) is the process of converting spoken language into written text almost instantaneously, with minimal delay between speech and the appearance of corresponding text. Unlike traditional transcription, which processes audio files after recording is complete, real-time transcription works as the audio is being produced.
Use Cases Across Industries
Real-time transcription has found applications in numerous sectors. Media and broadcasting utilize it for live captioning for news broadcasts and sports events. In education, it enables real-time note-taking for students and lecture transcription. Customer service departments implement it for live call transcription to aid in analysis and quality assurance. Healthcare professionals use it for medical dictation and telehealth consultations, while the legal industry relies on it for court reporting and depositions. Additionally, it provides essential accessibility services for people with hearing impairments and supports businesses in documenting meetings and conference calls.
Benefits of Implementing Real-Time Transcription
Real-time transcription makes audio content accessible to deaf and hard-of-hearing individuals while converting ephemeral spoken content into searchable text. It creates instant records of conversations and presentations, can facilitate translation between languages, and eliminates the delay of traditional transcription methods.
Technologies Powering Real-Time Speech to Text
Automatic Speech Recognition (ASR)
The core technology behind real-time transcription is Automatic Speech Recognition (ASR). ASR works by capturing audio input through a microphone or audio stream, converting the audio signal into digital data, processing the data through acoustic and language models, and generating text output based on the most probable interpretation.
Neural Networks and Deep Learning
Modern real-time transcription systems leverage neural networks and deep learning to achieve high accuracy. Recurrent Neural Networks process sequential data, capturing context in speech, while Convolutional Neural Networks extract features from spectrograms of audio. State-of-the-art transformer models have significantly improved transcription accuracy, and end-to-end models directly map audio features to text without intermediate phonetic representations.
Cloud-Based vs. On-Premise Solutions
When implementing real-time transcription, you have two primary deployment options:
Cloud-Based Solutions offer scalability, regular updates, and minimal infrastructure requirements, but come with internet dependency, potential latency, subscription costs, and data privacy concerns. Examples include Google Cloud Speech-to-Text, AWS Transcribe, and Microsoft Azure Speech Services.
On-Premise Solutions provide benefits like data privacy, no internet dependency, and potentially lower latency, but have disadvantages including higher upfront costs, maintenance responsibility, and limited scalability. Examples include Kaldi and Mozilla DeepSpeech for custom implementations.
Key Features to Look for in a Real-Time Transcription Service
When selecting a real-time transcription solution, consider critical features like accuracy (percentage of words correctly transcribed), latency (delay between speech and transcription), speaker diarization (ability to identify different speakers), punctuation and formatting capabilities, language support, customization options, and integration capabilities.
Implementing Real-Time Transcription: A Step-by-Step Guide
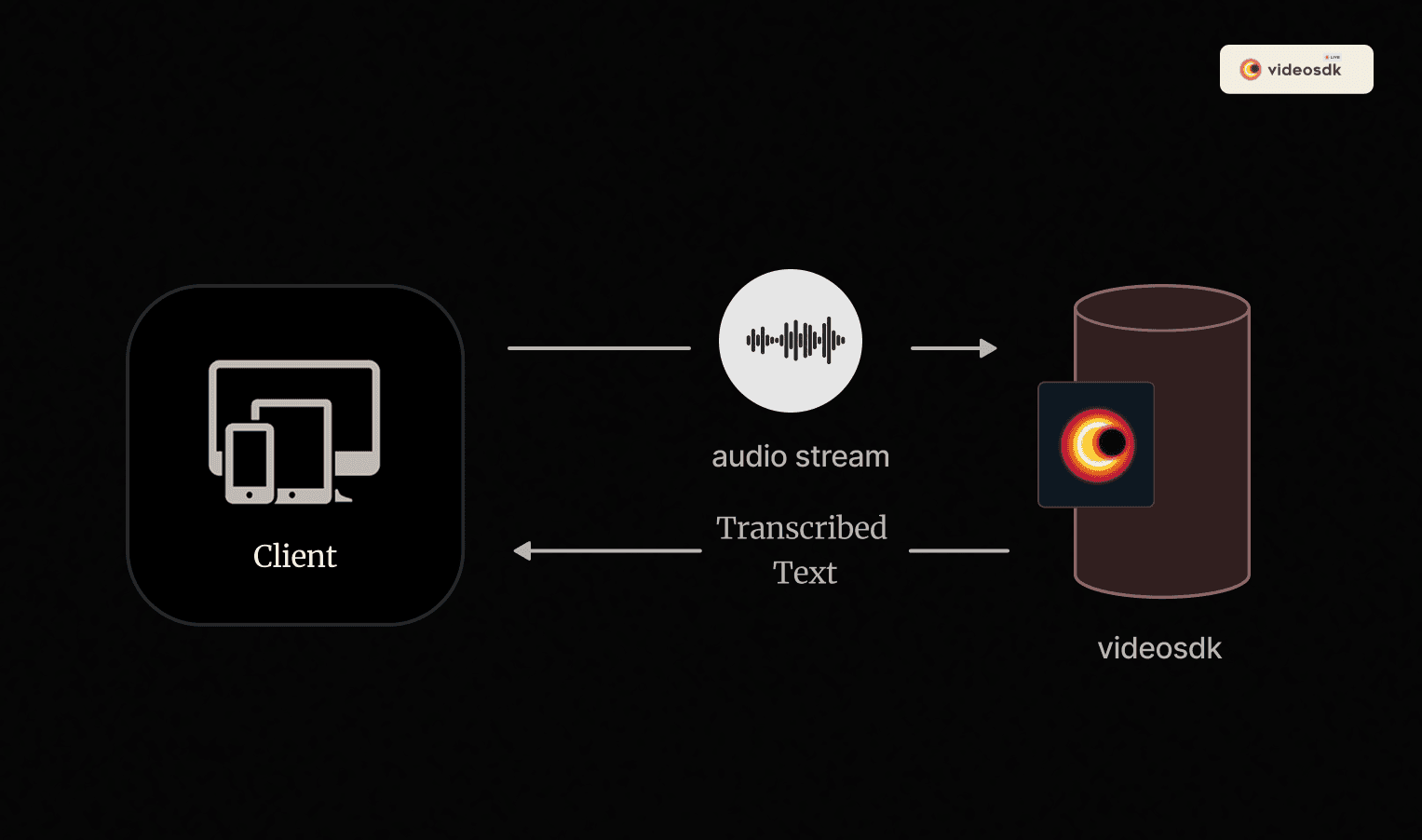
1. Defining Your Requirements
Before implementation, clearly define your specific use case and goals, required accuracy level and acceptable latency, languages and dialects needed, expected volume of audio to be processed, and budget constraints.
2. Choosing the Right Platform or API
Research available platforms based on your requirements, such as Google Cloud Speech-to-Text, AWS Transcribe, Microsoft Azure Speech Services, AssemblyAI, or VideoSDK, which offers real-time transcription optimized for video applications.
3. Setting Up the Environment
Once you've selected a platform, create an account and obtain API credentials, install necessary SDKs or libraries, configure authentication, and set up your development environment.
4. Integrating with VideoSDK
VideoSDK enables developers to enhance their video meeting applications with transcription capabilities. It provides both real-time transcription, where speech is converted to text during the meeting, and post-meeting transcription, which generates a detailed summary after the meeting.
Understanding Transcription States
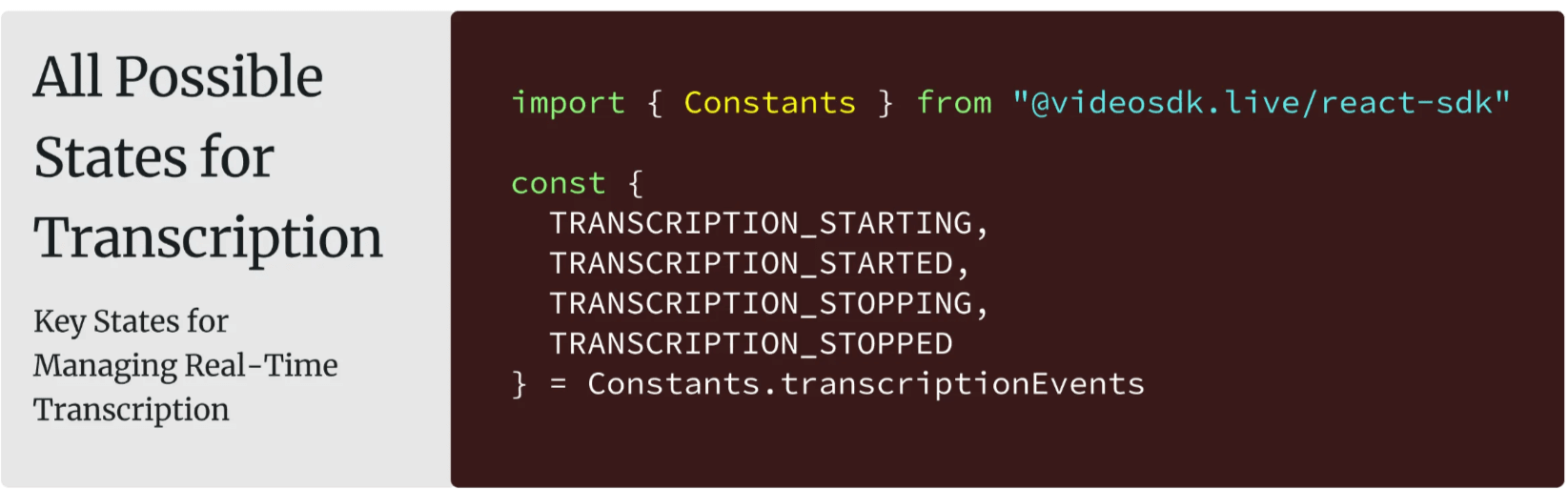
When implementing real-time transcription, it's important to understand the different states that your transcription service can be in. VideoSDK provides a clear state management system for transcription:
The transcription system moves through these states as you control the service:
1import { Constants } from "@videosdk.live/react-sdk"
2
3const {
4 TRANSCRIPTION_STARTING,
5 TRANSCRIPTION_STARTED,
6 TRANSCRIPTION_STOPPING,
7 TRANSCRIPTION_STOPPED
8} = Constants.transcriptionEvents
9Step 1: Setting Up the Transcription Hook
Let's implement real-time transcription using VideoSDK's
useTranscription hook. First, we'll set up the necessary imports and state variables:1import { useState } from 'react';
2import { useTranscription, Constants } from '@videosdk.live/react-sdk';
3
4export const MeetingView = () => {
5 // States to manage transcription
6 const [isTranscriptionStarted, setIsTranscriptionStarted] = useState(false);
7 const [isStarting, setIsStarting] = useState(false);
8 const [transcriptionText, setTranscriptionText] = useState('');
9Step 2: Implementing State Management
Next, we'll initialize the transcription handlers to manage state changes:
1 // Initialize transcription handlers
2 const { startTranscription, stopTranscription } = useTranscription({
3 onTranscriptionStateChanged: (state) => {
4 const { status } = state;
5
6 // Update states based on transcription status
7 if (status === Constants.transcriptionEvents.TRANSCRIPTION_STARTING) {
8 setIsStarting(true);
9 } else if (status === Constants.transcriptionEvents.TRANSCRIPTION_STARTED) {
10 setIsTranscriptionStarted(true);
11 setIsStarting(false);
12 } else if (status === Constants.transcriptionEvents.TRANSCRIPTION_STOPPING) {
13 console.log('stopping real-time transcripton')
14 } else {
15 setIsTranscriptionStarted(false);
16 setTranscriptionText(''); // Clear text when transcription stops
17 console.log('real-time transcription is stopped!')
18 }
19 },
20 onTranscriptionText: (data) => {
21 const { participantName, text } = data;
22 console.log(participantName, text);
23 // Update transcription text in real time
24 setTranscriptionText(text);
25 },
26 });
27Step 3: Creating the Control Function
Now, we'll implement a function to handle starting and stopping transcription:
1 // Toggle transcription on or off
2 const handleTranscription = () => {
3 const config = {
4 webhookUrl: null,
5 summary: {
6 enabled: true,
7 prompt:
8 'Write summary in sections like Title, Agenda, Speakers, Action Items, Outlines, Notes and Summary',
9 },
10 };
11
12 if (!isTranscriptionStarted) {
13 startTranscription(config);
14 } else {
15 stopTranscription();
16 }
17 };
18Step 4: Rendering the UI Components
Finally, we'll create the UI for controlling and displaying transcription:
1 return (
2 <>
3 {/* Transcription and meeting controls */}
4 <div>
5 <button onClick={handleTranscription}>
6 {isTranscriptionStarted
7 ? 'Stop Transcription'
8 : isStarting
9 ? 'Starting...'
10 : 'Start Transcription'}
11 </button>
12
13 {/* Transcription display */}
14 {isTranscriptionStarted && <div>{transcriptionText || 'Listening...'}</div>}
15 </div>
16 </>
17 );
18};
195. Implementing Post-Meeting Transcription
VideoSDK also provides functionality for post-meeting transcription with summaries. This feature can be implemented using the
useMeeting hook to automatically generate transcription summaries after a recording ends.Step 1: Setting Up the Recording Hook
First, let's set up the necessary imports and state variables:
1import { useState } from 'react';
2import { useMeeting } from '@videosdk.live/react-sdk';
3
4export const MeetingView = () => {
5 // States to manage recording
6 const [isRecording, setIsRecording] = useState(false);
7 const [isRecordStarted, setIsRecordStarted] = useState(false);
8Step 2: Initializing Recording Controls
Next, we'll set up the recording controls with event handlers:
1 // Initialize recording methods and event handlers
2 const { startRecording, stopRecording } = useMeeting({
3 onRecordingStarted: () => setIsRecording(true),
4 onRecordingStopped: () => {
5 setIsRecording(false);
6 setRecordingTime(0); // Reset timer
7 }
8 });
9Step 3: Configuring Recording with Transcription
Now, we'll create a function to handle recording with transcription settings:
1 const handleRecording = () => {
2 // Storage configuration
3 const webhookUrl = null;
4 const awsDirPath = null;
5
6 // UI configuration for recording output
7 const config = {
8 layout: {
9 type: "GRID",
10 priority: "SPEAKER",
11 gridSize: 4,
12 },
13 theme: "DARK",
14 mode: "video-and-audio",
15 quality: "high",
16 orientation: "landscape",
17 };
18
19 // Post-meeting transcription summary configuration
20 const transcription = {
21 enabled: true,
22 summary: {
23 enabled: true,
24 prompt:
25 "Write summary in sections like Title, Agenda, Speakers, Action Items, Outlines, Notes and Summary",
26 },
27 };
28Step 4: Implementing Recording Control Logic
Finally, we'll add the logic to start and stop recording:
1 if (!isRecording) {
2 // Start recording with transcription
3 startRecording(webhookUrl, awsDirPath, config, transcription);
4 } else {
5 // Stop recording
6 stopRecording();
7 }
8 setIsRecordStarted(!isRecordStarted);
9 };
10
11 return (
12 <>
13 {/* Recording UI control */}
14 <div>
15 <button onClick={handleRecording}>
16 {isRecording ? "Stop" : "Start Recording"}
17 </button>
18 </div>
19 </>
20 );
21};
22Optimizing Real-Time Transcription Accuracy and Performance
Audio Quality Optimization
Audio quality significantly impacts transcription accuracy. Use high-quality microphones with noise cancellation and ensure you're minimizing background noise and echo. Apply audio processing techniques like noise reduction and speech enhancement when possible. Using an adequate sampling rate (typically 16kHz or higher) and positioning microphones close to speakers will also improve results.
Customization and Training
Enhance accuracy through customization by adding domain-specific terms, acronyms, and proper nouns to your vocabulary. Provide likely phrases to bias recognition, fine-tune acoustic models for specific speakers or environments, and optimize language models for domain-specific language patterns.
Handling Errors and Corrections
No transcription system is perfect, so implement strategies to handle inevitable errors. Create a real-time editing interface allowing users to correct errors as they appear, apply automatic correction for known error patterns, use confidence scores to filter or highlight words with low confidence, and implement feedback loops to improve future transcriptions.
Challenges and Considerations
Accuracy and Latency Challenges
Real-time transcription faces several challenges with accuracy and latency. Variations in pronunciation, background noise, overlapping speech, technical terminology, and irregular speech patterns all affect transcription quality. Meanwhile, network conditions, processing power, model complexity, and audio buffering can all impact latency.
Security and Privacy
When implementing real-time transcription, it's crucial to consider security aspects. Ensure audio and transcription data is encrypted, define clear data retention policies, adhere to relevant regulations like GDPR or HIPAA, obtain appropriate permissions for recording and transcribing, and implement robust access controls.
Cost Considerations
Real-time transcription costs vary based on several factors. These include volume-based pricing (cost per hour of audio processed), feature-based pricing (additional costs for premium features), subscription models (monthly or annual commitments), on-premise costs (hardware, software, and maintenance), and development resources needed for integration and customization.
Conclusion
Implementing real-time transcription represents a powerful way to enhance accessibility, improve documentation, and enable new forms of communication. As ASR technology continues to advance, we can expect even more accurate, faster, and more versatile transcription capabilities.
Whether you're building a video conferencing platform, creating accessibility tools, or enhancing customer service systems, real-time transcription can provide significant value. By following the implementation guidelines outlined in this article and addressing the challenges proactively, you can successfully integrate this transformative technology into your applications.
Building a meeting application with advanced features like recording, real-time transcription, and post-recording summaries is made straightforward with VideoSDK. The ability to capture live transcripts during a meeting improves accessibility and engagement, while the post-recording transcription and summary functionality provide a structured overview of the session. This combination of real-time and post-event insights ensures that meetings are not only productive but also well-documented, offering value long after the discussion ends.
Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights
FAQ