Imagine a doctor dictating complex patient notes, a lawyer recording key details during a deposition, or a business team trying to capture every insight from a brainstorming session. In each scenario, converting spoken words into accurate text is essential. But how does transcription work in today's digital landscape, and how has transcription technology evolved to meet growing demands for speed and accuracy?
In this guide, we'll explore the mechanics behind transcription, focusing on cutting-edge real-time transcription technologies that are transforming how we capture and process spoken language. Whether you're considering implementing transcription in your organization or simply curious about how these systems function, this comprehensive overview will provide valuable insights into modern transcription processes.
The Evolution of Transcription: From Manual to Automated
Traditional Transcription Processes
Traditionally, transcription was an entirely manual process. A person would listen to audio recordings, often using specialized equipment like foot pedals to control playback, and type what they heard. This approach required skilled professionals with expertise in listening, typing, language comprehension, and often domain-specific knowledge.
While human transcriptionists still play a critical role in many contexts, this approach has significant limitations. Manual transcription is time-consuming, typically requiring 4-6 hours of work per hour of audio. It's also expensive and doesn't scale easily to meet large-volume demands, creating bottlenecks for organizations that need quick turnaround times.
The need for specialized knowledge further complicates the process. Medical transcriptionists need extensive knowledge of terminology and abbreviations, while legal transcriptionists must understand complex legal terms and formatting requirements. This specialization increases costs and limits the availability of qualified professionals.
The Rise of Automated Speech Recognition (ASR)
The development of Automated Speech Recognition (ASR) technology marked a revolutionary shift in how transcription works. Instead of relying solely on human effort, ASR systems use sophisticated algorithms to convert spoken language into text automatically.
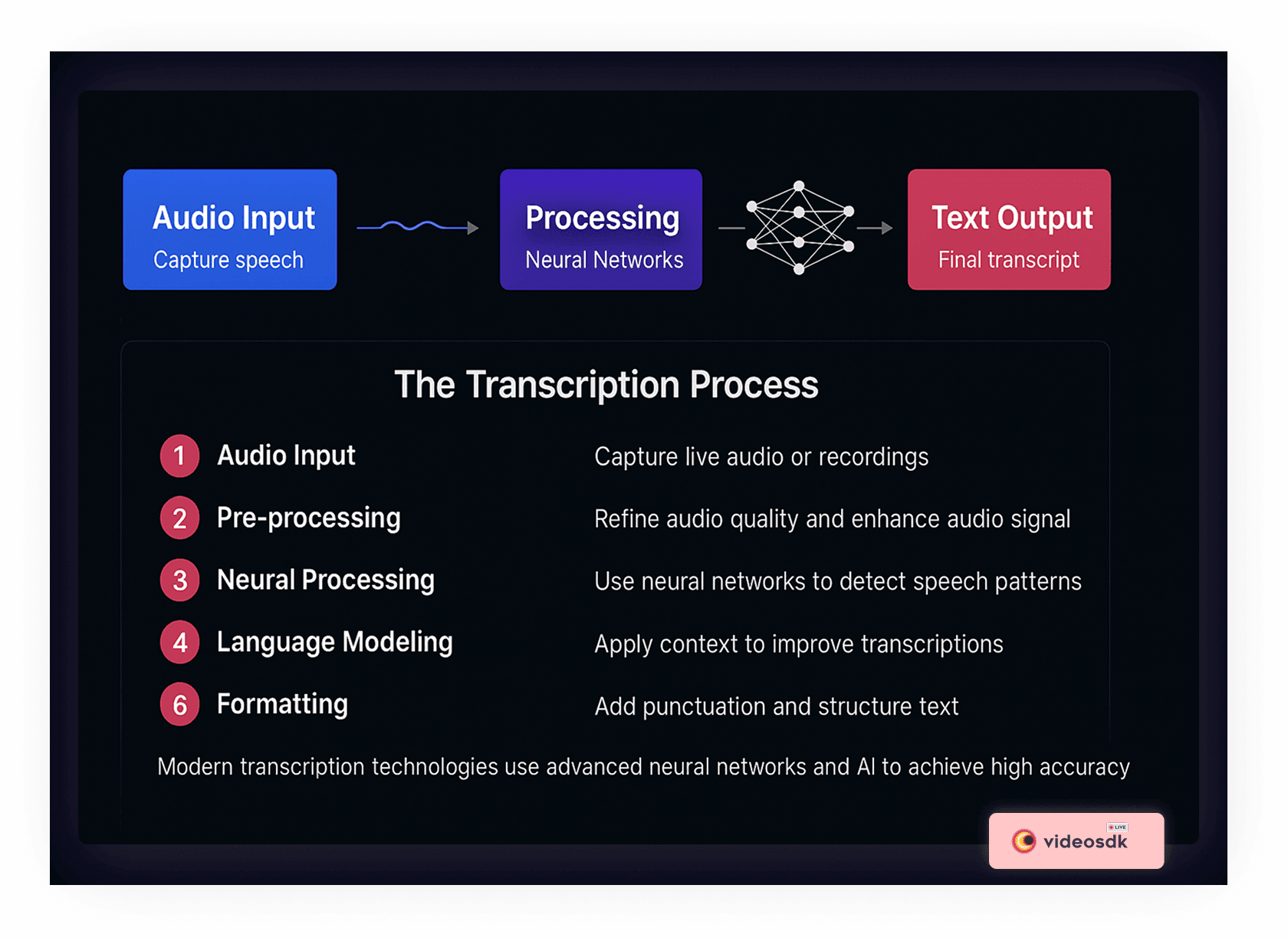
Modern ASR systems follow a multi-stage process:
- Audio Input: The system receives audio from recordings or live microphone feeds
- Pre-processing: Background noise is reduced, and the audio signal is enhanced
- Feature Extraction: The audio is broken into small segments and converted into numerical representations
- Acoustic Modeling: These features are matched against learned patterns of speech sounds
- Language Modeling: The system determines the most likely word sequences based on context
- Text Output: The final text is generated, often with confidence scores for each word
This process has become increasingly sophisticated with the advancement of machine learning and artificial intelligence, dramatically improving accuracy and reducing processing time. Modern ASR systems can now achieve accuracy rates that rival human transcriptionists in many contexts, particularly for clear audio with standard accents and terminology.
Understanding Modern Transcription Technology
Today's advanced transcription systems leverage several key technologies that work together to achieve high accuracy and efficiency.
Deep Learning and Neural Networks
Modern transcription systems are powered by deep neural networks that learn from vast quantities of data, recognizing patterns and improving performance over time. These systems employ three main neural network architectures:
Recurrent Neural Networks (RNNs) process sequential data, making them well-suited for understanding speech. They maintain memory of previous inputs, allowing them to understand context and make better predictions based on what came before.
Convolutional Neural Networks (CNNs) identify patterns in audio spectrograms—visual representations of sound frequencies over time. They excel at identifying phonetic patterns regardless of their position in the audio, helping handle variable speech rates and accents.
Transformer Models have revolutionized natural language processing with their ability to understand context within sequences. They use an "attention" mechanism to weigh the importance of different parts of the input, significantly improving accuracy by helping the system understand words based on the broader context of the conversation.
These neural networks recognize speech patterns across different accents, speaking styles, and acoustic environments, continually adapting to new data to improve performance.
Language Processing and Context Analysis
Beyond simply converting sounds to words, advanced transcription technology uses natural language processing (NLP) to understand context and improve accuracy:
- Language Models predict probable word sequences, distinguishing between similar-sounding phrases based on context
- Contextual Understanding identifies domain-specific terminology and adjusts recognition accordingly
- Automatic Punctuation adds appropriate punctuation marks based on speech patterns and pauses
- Speaker Diarization identifies and labels different speakers in multi-person recordings
This contextual understanding significantly improves the readability and usefulness of transcripts, transforming raw text into properly formatted documents that accurately capture not just words but meaning.
Cloud-Based Processing
Most modern transcription systems leverage cloud computing, providing several advantages:
- Scalable processing power for handling large volumes of transcription
- Continuous model improvements without requiring user downloads
- Accessibility from any device with internet connectivity
- Easy integration with other business systems through APIs
This cloud approach has democratized access to powerful transcription capabilities, making them available to individuals and small organizations that couldn't otherwise afford the necessary computing infrastructure.
The Revolution of Real-Time Transcription
One of the most significant advances in transcription technology is the development of real-time capabilities. Real-time transcription converts spoken words to text as they're being spoken, with minimal delay.
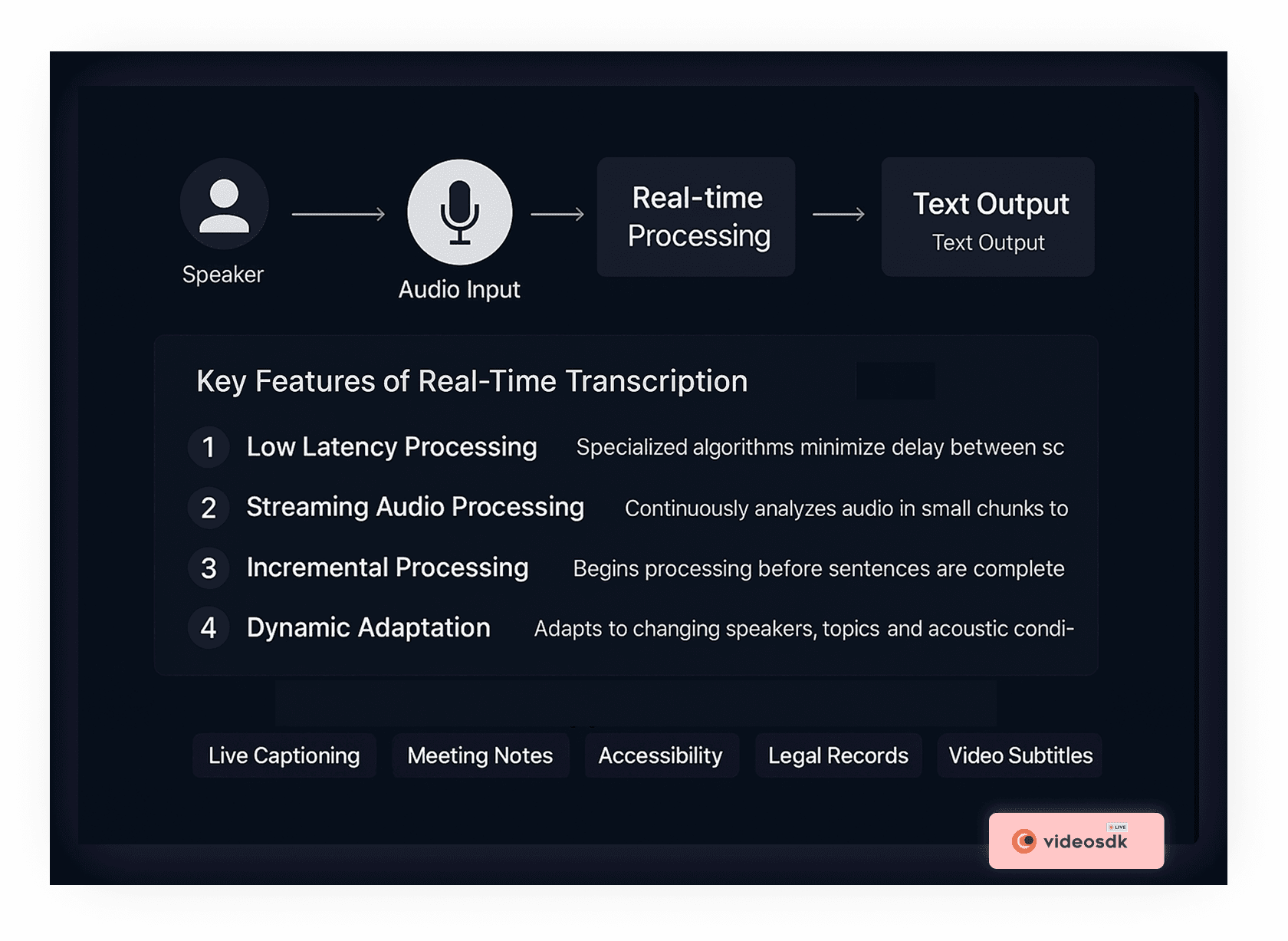
How Real-Time Transcription Works
Real-time transcription operates on similar principles to standard ASR but faces additional challenges due to the need for immediate processing:
- Streaming Audio Processing: The system analyzes continuous audio streams in small chunks rather than waiting for complete recordings
- Low-Latency Algorithms: Specialized algorithms minimize the delay between speech and text output, typically aiming for under 300 milliseconds
- Incremental Processing: The system begins processing speech before the speaker has finished a sentence, making initial predictions that may be refined as more context becomes available
- Dynamic Adaptation: Real-time systems must adapt to changing speakers, topics, and acoustic conditions without interruption
- Confidence Thresholds: The system balances speed and accuracy by determining when to display words based on confidence levels
The result is a system that can display text almost instantaneously after words are spoken, enabling live captioning, meeting transcription, and accessibility applications that weren't possible with traditional transcription methods.
Key Components of a Real-Time Transcription System
To achieve true real-time performance, these systems rely on several critical components working together seamlessly:
Efficient Audio Capture: High-quality audio input is crucial for accuracy. This includes noise cancellation algorithms, audio preprocessing for clarity, and support for multi-microphone setups to capture all speakers in a room.
Distributed Processing Architecture: Real-time systems distribute processing across multiple components in a pipeline, allowing each stage to process data concurrently. This reduces overall latency as different parts of the audio stream are processed simultaneously at different stages.
Streaming APIs: These maintain persistent connections between the audio source and the transcription server, transferring audio data in small chunks and returning partial results as they become available. They can also update previously transcribed text as more context becomes available.
Responsive User Interface: A well-designed interface displays text as it's transcribed, updates corrections seamlessly, and often distinguishes between final and interim results through formatting or color coding.
Applications of Modern Transcription Technology
The advances in transcription technology have enabled numerous practical applications across industries:
Accessibility and Inclusion
Real-time transcription has become a powerful tool for accessibility:
- Live captioning for deaf or hard-of-hearing individuals
- Language support for non-native speakers
- Learning assistance for students with different needs
These applications create more inclusive environments while helping organizations comply with accessibility regulations.
Business and Productivity
Organizations leverage transcription to enhance efficiency:
- Automated meeting notes eliminate manual note-taking
- Searchable archives create institutional memory
- Business intelligence tools extract insights from transcripts
These applications transform conversations from ephemeral exchanges into valuable business assets that can be analyzed, searched, and referenced.
Media and Content Creation
Content creators benefit from streamlined workflows:
- Video producers create subtitles automatically
- Podcast creators make their content searchable
- Publishers repurpose spoken content into multiple formats
These tools help creators maximize the value and reach of their content while meeting accessibility standards.
Legal and Compliance
The legal sector relies on accurate transcription for:
- Real-time court reporting during proceedings
- Deposition documentation with high accuracy
- Compliance monitoring of regulated communications
These applications demonstrate how transcription supports the exacting documentation requirements of legal and regulatory environments.
Implementing VideoSDK's Real-Time Transcription
One of the most powerful ways to add real-time transcription to your applications is through VideoSDK, which offers a robust API for integrating transcription capabilities into video conferencing and media applications.
How VideoSDK's Transcription Works
VideoSDK's real-time transcription service works through a streamlined process:
- Initialization: Your application initiates transcription using the API
- Audio Streaming: The system captures audio from participants in real-time
- Cloud Processing: VideoSDK's servers process the audio through advanced neural networks
- Text Generation: Transcribed text is returned to your application with minimal latency
- Display Integration: Your UI displays the text in real-time, often with speaker identification
This process happens so quickly that users experience it as instantaneous, with text appearing on screen as they speak.
Code Example: Implementing Real-Time Transcription
Here's a basic example of how to implement real-time transcription with VideoSDK:
1// Import VideoSDK components
2import { useTranscription, Constants } from '@videosdk.live/react-sdk';
3
4// Component with transcription functionality
5const TranscriptionComponent = () => {
6 const [transcripts, setTranscripts] = useState([]);
7
8 // Configure transcription event handlers
9 const onTranscriptionStateChanged = (data) => {
10 const { status, id } = data;
11
12 if (status === Constants.transcriptionEvents.TRANSCRIPTION_STARTED) {
13 console.log("Transcription started:", id);
14 } else if (status === Constants.transcriptionEvents.TRANSCRIPTION_STOPPED) {
15 console.log("Transcription stopped:", id);
16 }
17 };
18
19 // Handle incoming transcription text
20 const onTranscriptionText = (data) => {
21 const { participantId, participantName, text, timestamp } = data;
22
23 setTranscripts(prevTranscripts => [
24 ...prevTranscripts,
25 { speaker: participantName, text, time: timestamp }
26 ]);
27 };
28
29 // Get transcription methods from the hook
30 const { startTranscription, stopTranscription } = useTranscription({
31 onTranscriptionStateChanged,
32 onTranscriptionText,
33 });
34
35 // Start transcription with configuration
36 const handleStartTranscription = () => {
37 const config = {
38 // Optional webhook URL for external processing
39 webhookUrl: null,
40
41 // Enable summary generation
42 summary: {
43 enabled: true,
44 prompt: "Summarize key points and action items"
45 }
46 };
47
48 startTranscription(config);
49 };
50
51 return (
52 <div>
53 <button onClick={handleStartTranscription}>Start Transcription</button>
54 <button onClick={stopTranscription}>Stop Transcription</button>
55
56 <div className="transcripts">
57 {transcripts.map((item, index) => (
58 <div key={index} className="transcript-item">
59 <span className="speaker">{item.speaker}:</span>
60 <span className="text">{item.text}</span>
61 </div>
62 ))}
63 </div>
64 </div>
65 );
66};
67VideoSDK offers additional features like custom vocabularies, multi-language support, and integration with video conferencing functionality. The API abstracts away the complexity of speech recognition while giving developers control over the user experience.
Challenges and Limitations in Transcription Technology
Despite significant advances, transcription technology still faces several challenges:
Accuracy Challenges
Several factors can impact transcription accuracy:
- Accents and Dialects: Systems may struggle with less common accents and regional speech patterns
- Domain-Specific Terminology: Technical jargon and specialized vocabulary can be difficult to recognize
- Background Noise: Noisy environments continue to pose challenges for accurate transcription
- Multiple Speakers: Overlapping speech and speaker identification remain difficult problems
Technical Considerations
Implementing transcription technology requires addressing:
- Latency Management: Balancing speed and accuracy, especially in real-time applications
- Scalability: Handling multiple concurrent transcription sessions efficiently
- Integration Complexity: Connecting transcription services with existing systems
- Resource Requirements: Managing computing resources, especially for on-device transcription
Data Privacy and Security
Organizations implementing transcription must consider:
- Sensitive Information: Protecting personal or confidential information in transcripts
- Data Storage: Securely storing and managing transcript data
- Compliance Requirements: Meeting regulations like HIPAA, GDPR, or industry-specific standards
- Consent Management: Ensuring proper consent for recording and transcribing conversations
Future Trends in Transcription Technology
The field of transcription continues to evolve rapidly. Here are some emerging trends:
Multimodal Transcription
Future systems will combine audio with other data sources:
- Visual cues from video to improve speaker identification and detect non-verbal context
- Document context to enhance accuracy for domain-specific content
- Biometric integration to improve speaker attribution in multi-person scenarios
Edge Computing for Transcription
On-device processing is becoming more powerful:
- Processing on local devices eliminates network delays
- Keeping sensitive audio data on-device enhances privacy
- Offline capability enables transcription without internet connectivity
AI-Enhanced Post-Processing
Advanced AI will further refine transcription outputs:
- Better semantic understanding of context and meaning
- Automated summarization of long transcripts
- Extraction of action items and key decisions from meetings
Choosing the Right Transcription Solution
When selecting a transcription solution for your needs, consider these factors:
Accuracy Requirements
Different use cases have different accuracy thresholds:
- Critical Accuracy: Legal, medical, and compliance applications require near-perfect transcription
- General Purpose: Business communications can typically tolerate minor errors
- Draft Quality: Some applications only need the general content captured
Timing Needs
Consider your timing requirements:
- Real-Time: Live captioning, meeting assistance, and accessibility use cases
- Quick Turnaround: When transcripts are needed shortly after recording
- Batch Processing: When efficiency and cost are more important than immediate results
Integration and Customization
Evaluate how the solution will fit into your systems:
- Is the API robust enough for your integration needs?
- Can you customize the vocabulary for your domain?
- Does it support your required output formats?
Total Cost of Ownership
Look beyond the per-minute pricing:
- How costs scale with increased usage
- Additional fees for features like speaker identification
- Development resources needed for integration
Conclusion: The Future of Transcription Is Here
Understanding how transcription works reveals a technology that has evolved from a purely manual process to a sophisticated AI-driven capability. Modern transcription technology leverages deep learning, advanced language models, and cloud computing to achieve levels of accuracy and speed that were unimaginable just a decade ago.
Real-time transcription represents the cutting edge of this evolution, enabling applications that provide immediate text from spoken words. This technology is transforming how we communicate, collaborate, and create content across industries.
As we look to the future, the lines between human and automated transcription will continue to blur. The most effective approaches will likely combine AI efficiency with human expertise, providing the perfect balance of speed, accuracy, and understanding.
Whether you're considering implementing transcription for accessibility, productivity, or content creation, the technology has never been more capable or accessible. With solutions like VideoSDK, adding powerful transcription capabilities to your applications is simpler than ever, opening new possibilities for how we capture and utilize the spoken word.
FAQ