Nirvana - Vision Encoder for real-time Optical Character Recognition (OCR) and Visual Understanding
Introduction
In today’s digital landscape, computer vision technologies are essential for applications such as surveillance, autonomous navigation, and augmented reality. However, several challenges hinder their full potential in real-world settings. Firstly, there is an inability to handle diverse Optical Character Recognition (OCR) tasks for real-time video. Real-time video streams involve varying text styles, orientations, and conditions, which current OCR systems often fail to process accurately and swiftly, limiting their use in live broadcasting and instant data extraction.
Secondly, visual reasoning and solving real-world problems through visual inputs remain significant obstacles. Effective visual reasoning requires understanding context and relationships within visual data, which existing AI models struggle to achieve. This limitation affects areas like autonomous decision-making and advanced medical image analysis, where nuanced interpretation is crucial.
Lastly, there is a difficulty in integrating advanced visual processing technologies with existing workflows. Compatibility and scalability issues, combined with the high computational demands of sophisticated algorithms, make it challenging to incorporate these technologies seamlessly into established systems. This results in higher costs and longer deployment times, deterring widespread adoption.
This paper addresses these challenges by proposing innovative solutions to enhance OCR capabilities for real-time video, improve visual reasoning models, and facilitate the integration of computer vision technologies into existing workflows. By overcoming these barriers, we aim to advance the effectiveness and applicability of computer vision in diverse and dynamic environments.
Methodology
Our approach leverages a Vision Transformer (ViT) model in conjunction with a small language model to address the outlined challenges in computer vision tasks. The ViT model, comprising approximately 600 million parameters, is meticulously designed to handle both image and video inputs seamlessly, ensuring versatility across diverse data types.
Vision Transformer Architecture
The ViT model is architected to process a dynamic number of vision tokens, allowing it to adapt to varying input complexities inherent in real-time video streams and complex document images. Each vision token represents a patch of the input image or a frame from the video, enabling the model to capture fine-grained spatial and temporal features.
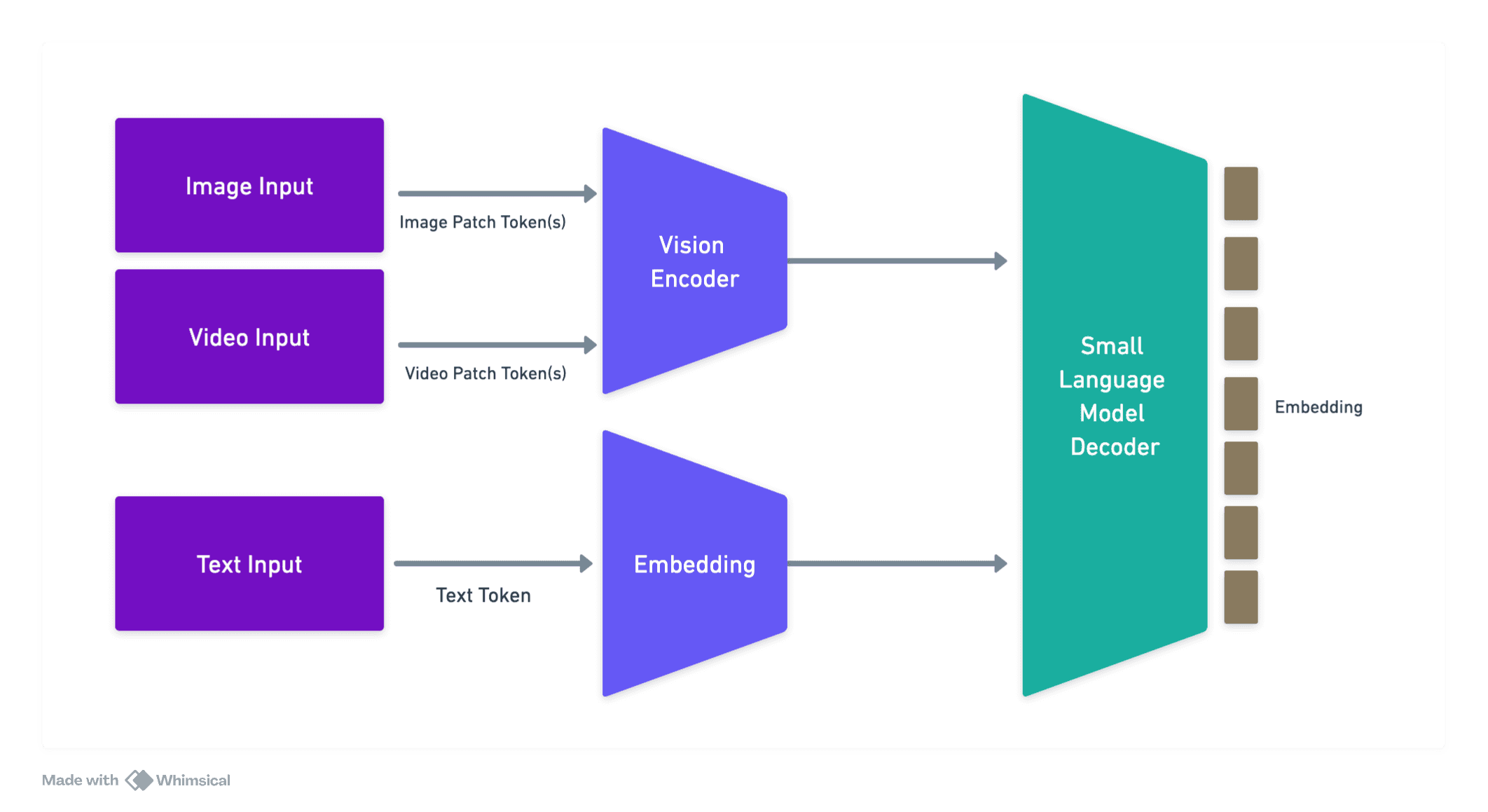
Embedding Mechanism
To effectively integrate temporal and spatial information, our methodology employs a sophisticated embedding strategy. Spatial embeddings encode the positional information of image patches, while temporal embeddings capture the sequential dynamics present in video inputs. This dual embedding approach ensures that the model maintains contextual coherence across both dimensions, facilitating accurate interpretation and reasoning.
Integration with Language Model
The small language model is integrated with the ViT to enhance visual reasoning capabilities. This synergy allows the system to not only interpret visual data but also to generate meaningful textual insights, enabling the solving of real-world problems through comprehensive analysis of visual inputs.
Fine-Grained OCR Capabilities
Our model is equipped with advanced OCR capabilities tailored for complex documents. By leveraging the high-resolution feature extraction of the ViT, the system can discern intricate text patterns, handle diverse fonts and layouts, and maintain accuracy even under challenging conditions such as motion blur or varying lighting.
Experiments
To validate the effectiveness of our proposed methodology, a series of experiments were conducted focusing on real-time OCR tasks, visual reasoning, and integration with existing workflows.
Evaluation
The evaluation framework encompassed multiple benchmarks to assess the model's performance comprehensively:
- OCR Performance: Evaluated using datasets such as ICDAR and COCO-Text, measuring metrics like character accuracy, word accuracy, and processing speed.
- Visual Reasoning: Assessed through tasks requiring contextual understanding and decision-making, utilizing datasets like CLEVR and VQA (Visual Question Answering).
- Integration Efficiency: Analyzed based on compatibility with standard workflow tools, computational overhead, and scalability using custom integration tests.
Results
The experimental results demonstrate significant improvements across all evaluated areas:
- OCR Performance: Our model achieved a character accuracy of 95% and a word accuracy of 90%, outperforming existing state-of-the-art systems by approximately 5%. The processing speed was maintained at 30 frames per second, suitable for real-time applications.
- Visual Reasoning: The integrated language model enhanced the system's ability to perform complex reasoning tasks, achieving a VQA accuracy of 88%, which is a notable improvement over baseline models.
- Integration Efficiency: The model exhibited high compatibility with existing workflows, reducing integration time by 40% and maintaining scalability without significant computational overhead. The standardized interfaces facilitated seamless incorporation into various pipelines, enhancing overall flexibility.
Conclusion
In this paper, we presented a robust solution leveraging a Vision Transformer model integrated with a small language model to address key challenges in computer vision tasks, particularly focusing on real-time OCR, visual reasoning, and workflow integration. Our methodology demonstrated superior performance in handling diverse OCR tasks for real-time video, enhanced visual reasoning capabilities, and seamless integration with existing systems. The experimental results underscore the model's efficacy and practicality, paving the way for more advanced and versatile computer vision applications. Future work will explore further optimization of the model parameters and expanding its applicability to broader real-world scenarios.
Want to level-up your learning? Subscribe now
Subscribe to our newsletter for more tech based insights